Byzantine Broadcast in Dolev-Strong Protocol
In this article, we study a classic result from 1983 by D.Dolev and H.Strong on reaching an agreement in a distributed system between a set of nodes “N” in the presence of faulty (Byzantine) nodes “F”.
Motivation: Understanding the Byzantine General Problem and Dolev-Strong Protocol is the gateway to getting a feel for how consensus protocol works, including more complicated models used in the blockchain space and distributed system. So in the spirit of building up your muscles, understanding this protocol will make life easier for you.
Content:
1. The Byzantine General Problem
- 1.1 Problem
- 1.2 Example
- 1.3 Approach
- 1.4 Questions:
2. Goals And Assumptions
- 2.1 Goals
- 2.2 Assumptions
- 2.3 Plan
3. Solving Via Round-Robin Leaders
- 3.1 A Lazy Protocol
- 3.2 Coordination via Rotating Leaders
4. Faulty/Byzantine Nodes
- 4.1- Types of faulty nodes
- 4.2- Failure of Rotating leader protocol in presence of faulty node
5. Byzantine Broadcast Problem
- 5.1- Cross-Checking
- 5.2- Byzantine Broadcast:
- 5.3- Goals of Byzantine Broadcast
- 5.4- Byzantine Broadcast + Rotating Leaders:
- 5.5- Implementation of Byzantine Broadcast Problem
6. Testing the protocol
- 6.1- Intuition: the f=1 case:
- 6.2- The f=2 case (the protocol fail)
7. The Dolev-Strong Protocol
- 7.1- Protocol Description
1. The Byzantine General Problem
1.1 Problem:
How to make absolutely sure that multiple entities, which are separated by distance are in absolute full agreement before an action is taken?
In other words, how can individual parties find a way to guarantee full consensus?
1.2 Example:
Imagine you’re a General in a Byzantine army and you’re planning to attack an enemy city.
You have the city surrounded by several other generals, each of them separated several miles from the other and you must decide as a group whether to attack or retreat.

Some generals may prefer to attack while others prefer to retreat. The important thing is that all generals agree on a common decision
A coordinated attack will lead to successful victory. An uncoordinated attack will lead to defeat.
1.3 Approach:
You have decided to attack the city but you have no means of communication to tell other generals your decision. How do you make sure then, that other generals reach a consensus and all attack together at the same time?
You could send messengers on horseback but you need also to have a reply from each of your generals confirming that they have received your message, which means they have to send messenger again to you on horseback.

1.4 Questions:
- What if one of your messengers is killed by other armies before or after delivering the message?
- What if a messenger is captured by the enemy and an imposter messenger with a fake reply (Retreat in our case instead of Attack) is sent back to you?
- How do other generals know that the messages that they received from you are genuine and haven’t been intercepted or altered by enemies? (Solved by digital signatures)
- What if other generals are Traitors, and they send back to you a message that they’re willing to attack while their intention is to Retreat?
This problem has remained unsolvable for years, and this is the core of consensus used in Bitcoin and distributed systems in general.
2. Goals And Assumptions
Let’s now get our hands dirty in solving this problem.
2.1 Goals:
- Goal #1: Consistency (Agreement): A system satisfies consistency if All nodes agree on the same value v*.
- Goal #2: Liveness (Validity): Every submitted value vi to at least one node is eventually added to all nodes' history.

2.2 Assumptions:
- Assumption #1: Permissioned Settings: We assume we have a priori know set of nodes {1, 2, …, n} before the start of the protocol.
- Assumption #2: Public Key Infrastructure: Each node i has a distinct public-private key pair denoted Pki/Ski pair. Pki is known to all nodes at the start of the protocol.
- Assumption #3: Synchronous: This protocol operates as a synchronous model. You can think of this model as making two sub-assumptions:
- Shared global clock: All nodes share a global clock, which means all the nodes always agree on what time step we’re in 0,1,2,3,…
- We’ll assume that every message sent by one node at time t arrive to recipient by time step t+1
- Assumption #4: All honest nodes (We gonna relax this assumption later): We will assume at the beginning that we don’t have Byzantine or faulty nodes which means all nodes run the intended protocol correctly without deviation.
2.3 Plan:
- Solve the Problem under these assumptions and then we’re going to relax the last assumption #4 of having all honest nodes.
3. Solving Via Round-Robin Leaders
3.1 A Lazy Protocol
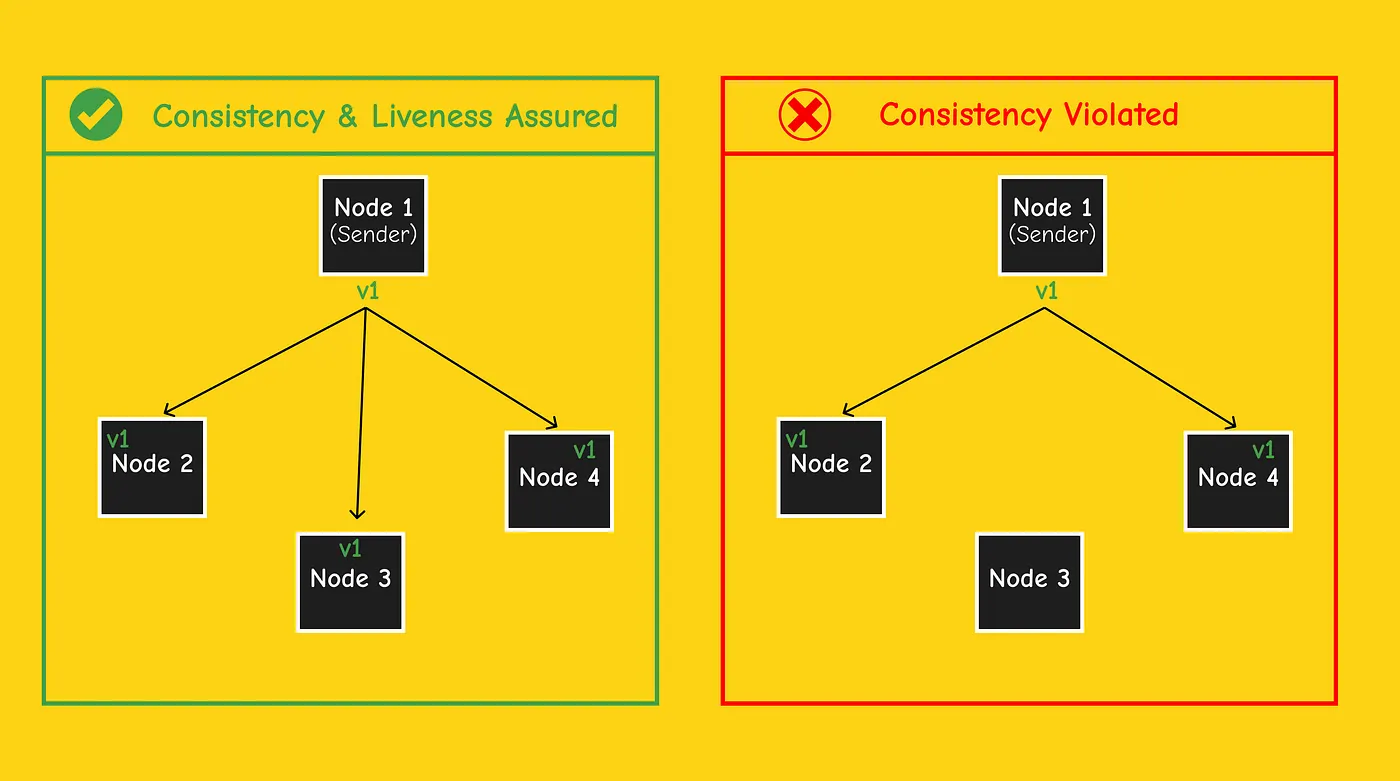
If every value submitted by a node (sender) always arrives at exactly the same time at every node, then the protocol is Valid (Consistency and liveness are satisfied).
But if a Node only submits a transaction to a subset of the nodes he’s connected to, or if the network delays because values arrive at different nodes in different time steps, then consistency will generally be violated.
3.2 Coordination via Rotating Leaders
The protocol above highlights the need for nodes to coordinate between them because not every node in our system will be connected to all n-1 other nodes (In the previous example Node 1 is not connected to Node 3, so Node 3 doesn’t receive the value v1, which break consistency at the end).
A solution for the problem above is to use a rotating leader for each step t. This means at time step t=t1, Node 1 sends value v1 to both nodes {2, 4}. At time step t=t+1 (t2), Node 2 will be the new sender and sends value v1 to the nodes he’s connected to.
We keep repeatedly iterating through the nodes in a round-robin order (Node 3 is the leader at time step 3, node x is the leader at time step x, …). In the last time step, all the nodes will have the same value v1, we then satisfied our goals (both consistency and validity are achieved).
Final Note: Under the 4 previous assumptions (Permissioned, PKI, Synchronous, and All honest nodes) Rotating leader seems to be a good protocol to achieve consistency and validity in a distributed system.
In the next section, we will relax the #4 assumption (all honest nodes) and see if this protocol is still valid in the presence of Faulty/Byzantine node.
4. Faulty/Byzantine Nodes
A node that is not honest is called a faulty node.
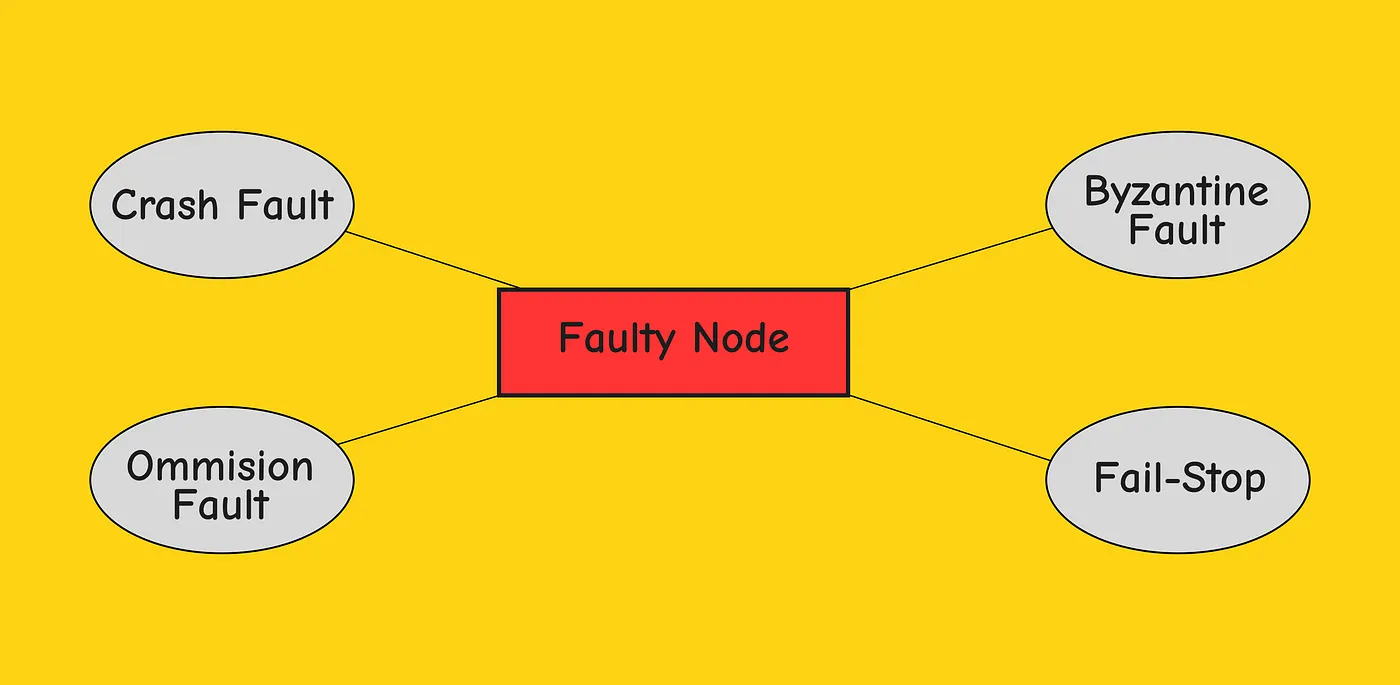
4.1- Types of faulty nodes:
- Crash Fault: A node halts, but silently. It occurs when a node simply stops working at some point in the protocol as if someone pulled out the plug. This means no more messages sent or received
- Omission Fault: A node fails to respond to incoming requests (arise from network delays or bad actor in the system)
- Byzantine Faults: Byzantine failures occur when a node does not behave according to its specific protocol or algorithm. This usually happens when a malicious actor or a software bug compromises the node.
- Fail-Stop: A node halts and remains halted permanently. Other nodes can detect that the node has failed (i.e., by communicating with it).
4.2- Failure of Rotating leader protocol in presence of faulty node
If we relax the last assumption #4 and we consider a system of n nodes with f are faulty nodes and n-f are honest, we can clearly see that our previous protocol of rotating leaders will fail.
Why? Byzantine nodes can ignore your protocol and do whatever they want, so at a time step t where a Byzantine (faulty) node is considered leader, it may send trickier values to other nodes, hence we haven’t achieved consistency and the protocol fail.
Solution: In the next section we will design a system that achieves consistency (agreement) and validity with the presence of f=1 faulty node.
5. Byzantine Broadcast Problem
5.1- Cross-Checking
Our simple rotating leaders' protocol achieves consistency and liveness when f=0 but not when f=1. So we need to come up with a more sophisticated protocol.
Here’s the idea of a new protocol: We can stick with the rotating leader approach where each node is considered a leader at a specific time step. However, instead of letting nodes blindly accept the new value received from the leader of the current time step, we will add a cross-checking functionality to make sure they don’t get tricked into inconsistency by a Byzantine sender node).
We will abstract this cross-checking functionality into a single-shot consensus problem called the Byzantine broadcast problem.
So combining Byzantine Broadcast (cross-checking functionality) with rotating leaders' ideas will make a perfect combo for a perfect fault-tolerant system.
Byzantine Broadcast + Rotating Leaders = Fault-tolerant System
5.2- Byzantine Broadcast:
Here’s the idea of Byzantine Broadcast:
We have a sender (known to all other nodes up front) with a private value v* (private means when the protocol begins only the sender knows what v* is) which belongs to some set V, and we want honest senders to broadcast their private value v* to all honest non-sender while also foiling byzantine sender who wants to trick honest nodes into inconsistency.
5.3- Goals of Byzantine Broadcast
- Goal #1: Termination:
Each honest node i eventually halts with some output vi ∈ V . (vi is node i’s best guess as to what the sender’s private input v∗ is.)
- Goal #2: Agreement (Consistency)
All honest nodes choose with the same value vi (whether or not the sender is honest).
- Goal #3: Validity (Liveness)
If the sender is honest, all honest nodes vi equal v∗ .
5.4- Byzantine Broadcast + Rotating Leaders:
Till now we solved half the equation Byzantine Broadcast + Rotating Leaders = Fault-tolerant System.
Let’s add rotating leaders to solve the state machine replication problem to create a perfect fault-tolerant system.
Design The System:
At each time step 0, T, 2T, 3T, . . . that is a multiple of T
(1) Define the current leader node using a round-robin order. (With node 1 the leader at time step 0, node 2 the leader at time step T, and so on.)
(2) The leader collects together all the not-yet-included values that it has heard about and assembles them into an ordered list L∗ .
(3) Invoke the protocol we defined above for the Byzantine broadcast problem, with the leader node acting as the sender and with the list L∗ as its private input.
(4) When the protocol terminates, every node i appends its output Li in the Byzantine broadcast problem to its local history.
Why this System is Correct?
Under the above-mentioned assumptions (Permissioned, PKI, Synchronous) this system satisfies consistency and liveness.
Proof:
- Consistency: every step, all honest nodes add the same value to the list L.
- Validity: if the honest node knows about a value v*, eventually will become the leader/sender at a time step T, and since the node is
honest all other honest nodes will add that value
PS: The protocol doesn’t care about how Byzantine nodes interact with the System, they can add anything to their local histories, and send any fake value to other nodes. As long as we can satisfy consistency between honest nodes, then the protocol works.
So to produce a fault tolerance system all we should come up with is an implementation of the Byzantine Broadcast (BB) Problem. Solving the BB problem will lead us to a fault-tolerant system via rotating leaders. But How do we do that?
5.5- Implementation of Byzantine Broadcast Problem
We already know how to solve the Byzantine Broadcast problem in the case of f=0 (no faulty node). The sender sends a private value v* and eventually all nodes output whatever they heard from the sender.
This system doesn’t work in f=1 case (presence of a faulty node), because a Byzantine sender can send different values to different nodes leading to inconsistency in the protocol.
To solve this issue we will add the cross-checking functionality we talked about early. When a sender send a private input v*, all honest non-sender should compare their value, to check if they have all received the same value from the sender or not. The trickiest part is that, there may be a Byzantine non-sender who lies during the cross-checking phase and frame an honest sender.
Using the Assumption #2 (Public Key Infrastructure), here’s a way to implement the cross checking functionality:

6. Testing the protocol
6.1- Intuition: the f=1 case:
Let’s test our protocol in the presence of n≥4 nodes, one of them is faulty f=1, and see if it satisfies Agreement and Validity and Termination.
- Termination: The protocol terminates, after three time steps, we will see why.
- Validity: To satisfy validity, we only care about the case when the sender is honest. The sender will send value v* along with its digital signature to all other non-sender. we should prove that all other honest non-sender output vi=v*. In the first time step each honest non-sender receives one vote for v* signed by the honest sender. In the second time step, each honest non-sender receive at least one more vote for v* echoed and signed by another honest non-sender (because n≥4 and f=1, so there is at least one other honest non-sender). In the third time step using the majority vote computation all honest non-sender will output v* (each honest-non sender will have at least 2 votes for v*. A Byzantine non-sender is powerless to contribute a false vote given the PKI assumption). (validity proof completed)
- Agreement: To satisfy the agreement, we only care about the case when the sender is Byzantine, (the other case where the sender is honest is already proved in Validity). Because f=1, every other non-sender n-1 are honest. In the first time step, let’s say that the Byzantine sender sent different values to different honest non-sender to break consistency. In the second time step, every honest non-sender will echo the value received to other honest non-senders. In the third time step, all honest non-sender will already have the same information. thus all honest non-sender carry out the same majority computation and output the same final output. (Agreement proof completed)
6.2- The f=2 case (the protocol fail):
Do you think this protocol will still hold in the case of f=2 faulty nodes? The answer is NO (Kudos if you see why).
A conspiracy and coordination between two byzantine nodes will break the protocol.
Assume that we have at least 4 nodes n=4, Two of them are Byzantines f=2, here’s how the 2 faulty nodes can break the protocol.

It seems that with we need more than one round of cross-checking to solve the incosistency between honest nodes. This is exactly what happens in Dolev Strong Protocol
7. The Dolev-Strong Protocol
We will see that the Dolev String protocol gives a solution to state machine replication. Worth mentioning that the protocol works only under the assumption of the Synchronous, Permissioned model and assuming the PKI.
7.1- Protocol Description

Let’s prove that the protocol works:
Validity:
Assume that the sender is honest, at time step 0 the sender will send a signed copy v* to all the non-sender, and because the signature can’t be forged, all nodes will receive the same output v* before the beginning of the next step t = 1.
Agreement:
Assume that the sender is byzantine (If the sender is honest validity implies agreement).
We need to prove that if a non-sender i get’s convinced of a value v by a message m, all other honest non-senders get convinced of that value v before the end of the protocol.
- t ≤ f: in this time step the protocol has not yet ended, so if a non-sender i gets convinced of a new value v by a message m, it sends this value and adds his signature to the message m. Every other honest non-sender j receives this message prior to the time step t+1. This signed message is first signed by the sender and at least t other distinct nodes. If the message includes j signature that mean node j already gets convinced of this value at some early point in time. Otherwise, j becomes convinced of v at time step t+1.
- t = f+1: in this case, if i becomes convinced of a new value v, there is no time for i to notify other nodes. So the only hope is that i i late in the party and other nodes already added v independently (either on time step t+1 or early)
Final Note:
This article uses extensively lectures by Tim Roughgarden on “Foundation of Blockchain” (check Reference) and other research papers.
Reference:
- https://www.cs.huji.ac.il/~dolev/pubs/authenticated.pdf
- https://timroughgarden.github.io/fob21/l/l2.pdf
- https://www.youtube.com/watch?v=dfsRQyYXOsQ
- https://vitalik.ca/general/2018/08/07/99_fault_tolerant.html
- https://spacemesh.io/blog/byzantine-agreement-algorithms-and-dolev-strong/
KEEP IN TOUCH
Follow me on Twitter for more decentralize thoughts :)
