Major Improvement of Initial Block Download (IBD)
When a Bitcoin node joins the network, it must synchronize with network by downloading the entire block chain (which is roughly 550 gigabytes now). This process, known as Initial Block Download (IBD), can be time-consuming and resource-intensive.
During the download, there could be a high usage for the network and CPU (since the node has to verify the blocks downloaded), and the client will take up an increasing amount of storage space .
This lengthy process can discourage new users from running full nodes
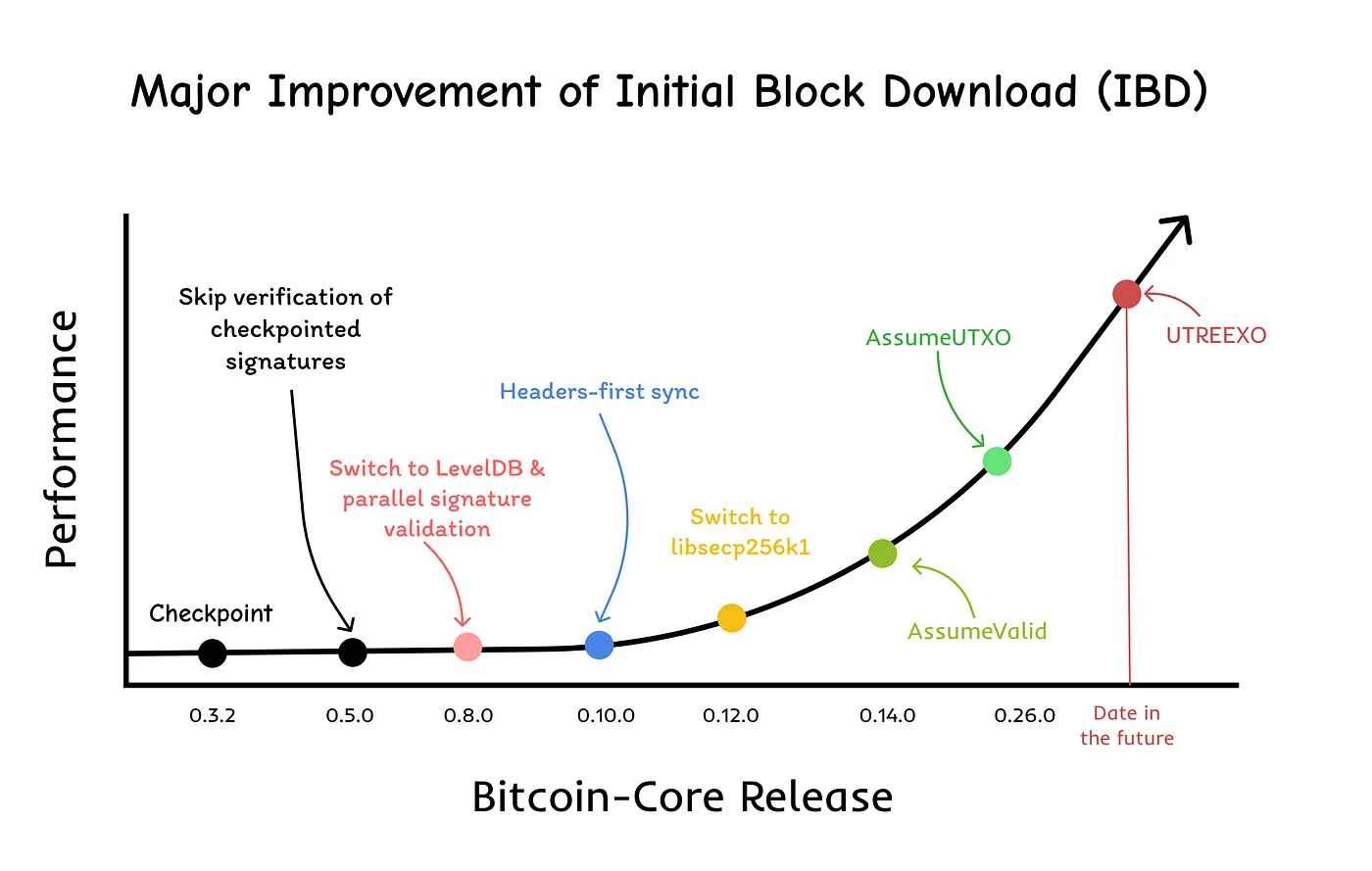
Various improvment emerged as a solution to streamline this IBD process, we will go through most of them starting from Bitcoin’s early release 0.3.2, which introduced checkpoints, up to release 0.14.0, featuring AssumeUTXO.
Before diving in, let’s take a quick look at a graph that maps out the major updates to the IBD process in Bitcoin Core, which we’ll be discussing in this article.
The most Naive Approach for IBD
The most naive approach for IBD is downloading the entire block data (transactions, headers, and all) sequentially.
This means that nodes would start from the very first block created (the genesis block) and download every block in order up to the current one.
This approach has a flaw: a peer could easily generate a chain with low difficulty, mine millions of blocks, send you these fake blocks, and keep you busy with verification for an extended period with a wrong chain.
Note: This scenario specifically occurs if the node is eclipsed by the same attacker
To address this, the “Headers-First Sync” approach was introduced, where nodes download block headers before any block data.
Headers-First Sync
In Bitcoin Core 0.10.0, headers-first synchronization was intoduced, the idea is to first synchronizes only the block headers which are 80 bytes each and allow the node to pre-filter orphaned blocks and dead sidechains, before downloading all the blocks data.
Bitcoin Core now uses ‘headers-first synchronization’. This means that we first ask peers for block headers and validate those. In a second stage, when the headers have been discovered, we download the blocks. However, as we already know about the whole chain in advance, the blocks can be downloaded in parallel from all available peers.
This will help us fix the problem with a dishonest peer feeding us a fake chain and wasting our resources in validation. we can now just compare header chains from mutliple peers to detect dishonest nodes and ensure integrity.
Okay headers-first sync looks great, but we want more speeeeeed ;)
Before we delve into the latest solutions for enhancing the IBD process, let me give you a brief history of significant improvements aimed at reducing the IBD challenges in previous Bitcoin releases.
Note: I won’t cover every detail of each release as some of them are self-explanatory. Instead, we’ll focus on recent updates such as assumeValid and assumeUTXO.”
Another Note: I might share an illustration about checkpoints later on. Stay tuned here for more insights and updates.
But wait, what about -dbcache option ?!!
Bob, with a high-RAM modern computer, can optimizes his Bitcoin node’s setup by increasing the -dbcache setting instead of keeping it with default value of 450Mb, this allows Bitcoin core to take more memory.
This is Benenficial because it directly impacts the amount of data the node can keep in RAM, rather than relying on slower disk I/O (Input/Output) operations
Explain more pls :
Faster Access: Data stored in RAM is accessed much faster than data stored on a disk. By increasing dbcache, you allow more data (like blocks and transactions) to be stored in RAM.. This means the node can process transactions and blocks quicker because it doesn't have to wait for the data to be read from or written to the disk.
Reduced Disk I/O: Disk I/O operations are significantly slower than memory operations and can become a bottleneck, especially during the initial block download (IBD) when the node is processing a large volume of data. High disk I/O can slow down the synchronization process and also wear out the disk faster. By keeping more data in RAM with a higher dbcache, you reduce the reliance on disk I/O, speeding up the sync process and reducing disk wear.
Assume Valid (0.14.0 release)
A significant portion of the initial block download time is spent verifying scripts/signatures. To speed up more IBD, Bitcoin Core 0.14.0 introduced a feature called “Assume Valid”
This lets your Bitcoin software skip checking signatures for some blocks if you tell it that you already trust those blocks to be valid.
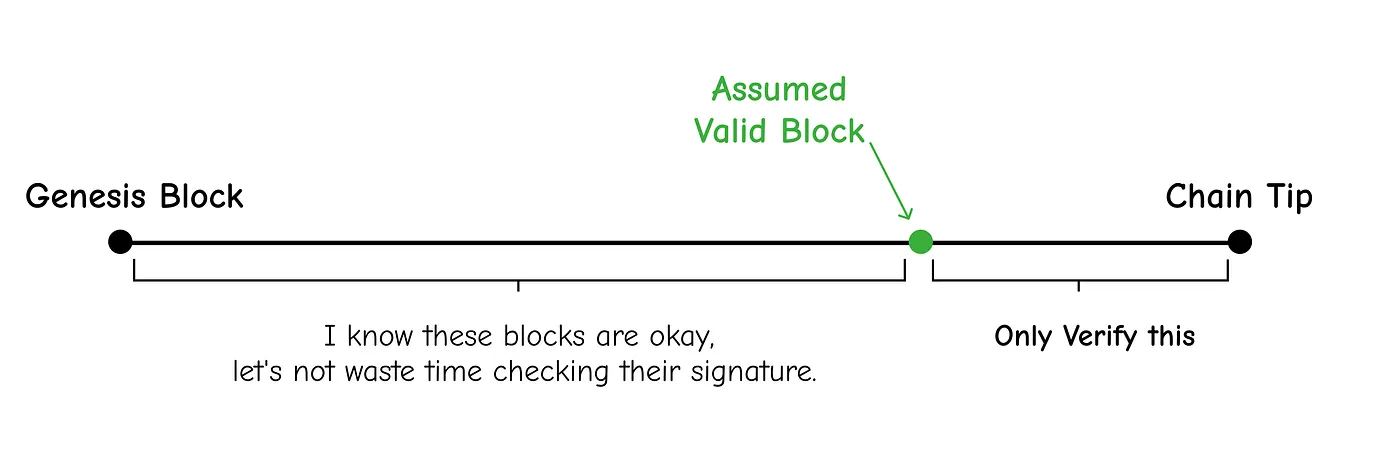
So If someone who starts a new full node for the first time knows about any valid blocks, they can then provide the highest-height one of those blocks to Bitcoin Core 0.14.0 and the software will skip verifying signatures in the blocks before the assumed valid block.
💡 All blocks after the assumed valid block will still have their signatures checked normally.
Example:
The default assumed valid block in Bitcoin Core 0.14.0 is #453354, 16 Februrary 2017, with hash 00000000000000000013176bf8d7dfeab4e1db31dc93bc311b436e82ab226b90
-assumevalid= 00000000000000000013176bf8d7dfeab4e1db31dc93bc311b436e82ab226b90

AssumeValid Performace
It has been reported that synchronization using AssumeValid only took around 2/3 of the time with 0.14.0 (with AssumeValid feature) than with Bitcoin Core 0.13.2.
A test of the speed of the previous release (Bitcoin Core 0.13.2) compared to the speed of this Bitcoin Core 0.14.0 release was performed using Amazon EC2 virtual private servers, type t2.xlarge with four cores and 16 GB memory. All Bitcoin Core settings were left at their defaults.
- Bitcoin Core 0.13.2 took 1 day, 12 hours, and 40 minutes to complete IBD
- Bitcoin Core 0.14.0 took 0 days, 6 hours, and 24 minutes to complete IBD

AssumeUTXO
[DRAFT]
[Soon]
UTREEXO (Coming soon)
Utreexo optimizes Bitcoin’s storage by using Merkle trees to validate transactions.
Nodes don’t need to store the UTXO set anymore

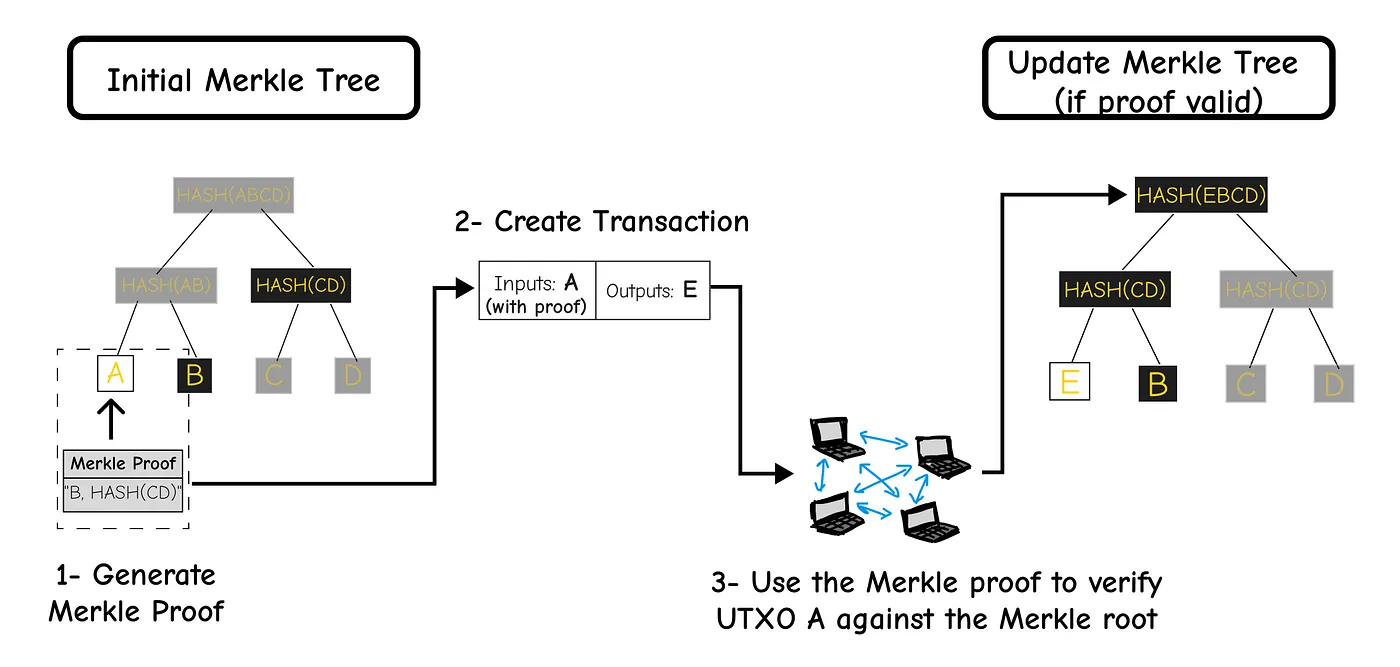
Let’s see how Bitcoin works today without Utreexo.
Say we have four UTXOs, A, B, C, and D.
Now Alice wants to send some bitcoins to Bob.
She creates a tx that spends UTXO A and creates a new UTXO E.
In the current Bitcoin protocol nodes will Update their UTXO set to {E, B, C, D}

Now, let’s introduce Utreexo
Instead of storing the UTXO set {A, B, C, D}
Nodes store a Merkle tree summarizing this set, The Merkle tree might look something like this:
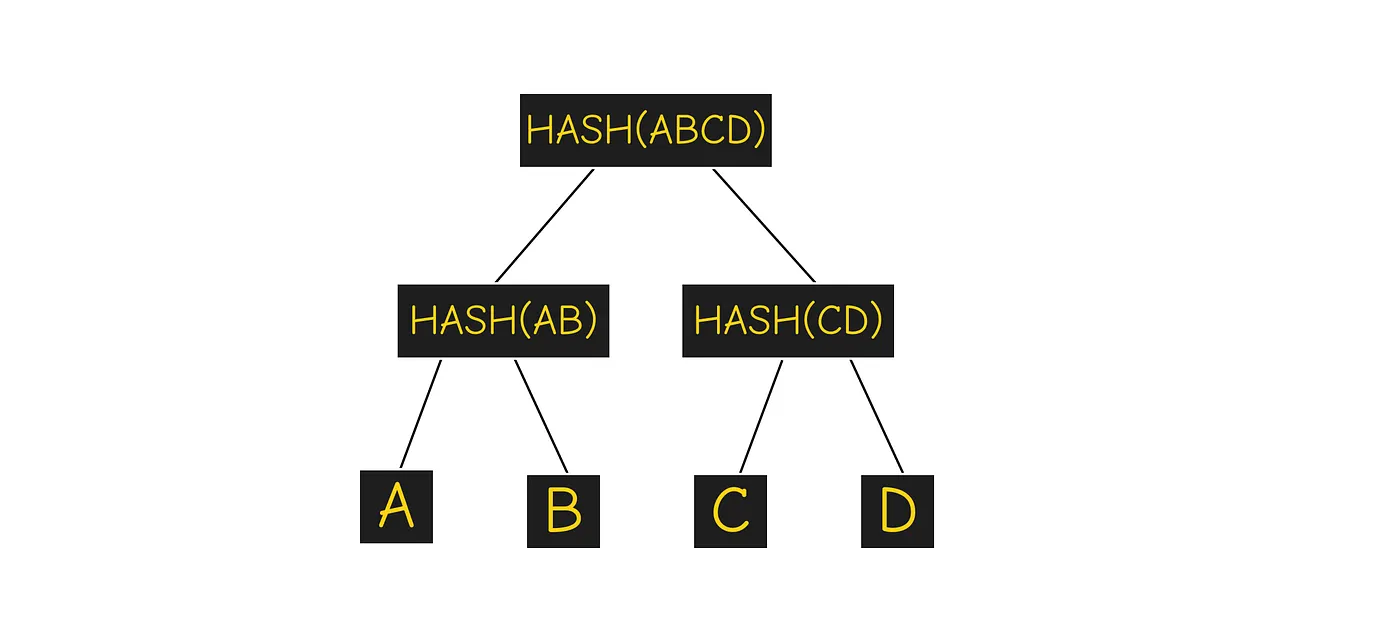
* A, B, C, and D are the hashes of the UTXOs,*
A Bitcoin node only needs to store the root of this tree, HASH(ABCD).
When Alice creates her transaction, she also generates a Merkle proof for UTXO A.
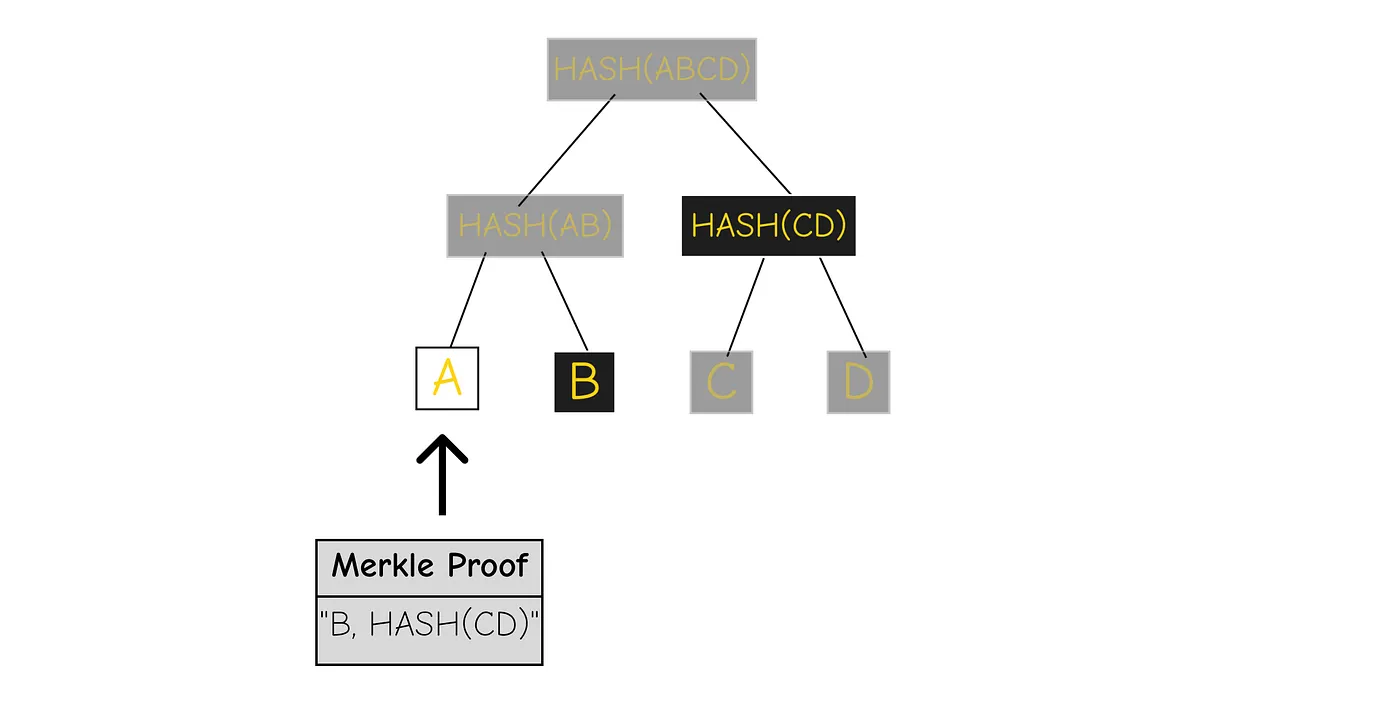
here’s a graph explaining the full process of updating the Merkle Tree.
For the exact algorithms, this gist is a good resource
https://gist.github.com/kcalvinalvin/a790d524832e1b7f96a70c642315fffc#file-utreexo-algorithms-md
